kernel pwn(三)防御机制
昨天的西湖论剑有一个kernel题(刚好最近阶段在冲kernel
写一下kernel_pwn的一些防御机制,wiki上面从隔离、访问控制、异常检测、随机化这四种方式来介绍内核中的防御机制。学习一下(照抄,
隔离
根据隔离的主体,隔离分为两种:
- 内核态和用户态的隔离
- 内核自身内部不同对象间的隔离
前面的文章也说到过保护机制KPTI/SMEP/SMAP
- 默认:用户态不可直接访问内核态的数据、执行内核态的代码
- SMEP:内核态不可执行用户态的代码
- SMAP:内核态不可访问用户态的数据
- KPTI:用户态不可看到内核态的页表;内核态不可执行用户态的代码(模拟)
SMEP
用户态的代码是可控的,假如控制了内核态的执行流程,就可以执行处理用户态的代码,非常容易受到攻击。所以这个保护就是让内核态不可执行用户态的代码。这个保护是与指令集架构相关的。
默认情况下SMEP是开启的,如果是使用 qemu 启动的内核,我们可以在 -append 选项中添加 +smep 来开启 SMEP。用下面的命令可以看到本机的SMEP是否开启。如果发现了 smep 字符串就说明开启了 smep 保护,否则没有开启。
1 | $ grep smep /proc/cpuinfo |
attack SMEP
把 CR4 寄存器中的第 20 位置为 0 后,我们就可以执行用户态的代码。一般而言,我们会使用 0x6f0 来设置 CR4,这样 SMAP 和 SMEP 都会被关闭。
内核中修改 cr4 的代码最终会调用到 native_write_cr4,当我们能够劫持控制流后,我们可以执行内核中的 gadget 来修改 CR4。从另外一个维度来看,内核中存在固定的修改 cr4 的代码,比如在 refresh_pce 函数、set_tsc_mode 等函数里都有。
SMAP
内核态可以访问用户态的数据的话。劫持控制流后,可以通过栈迁移将栈迁移到用户态,再后进行下一步攻击。所以就有了SMAP,这个防御措施的实现是与指令集架构相关的。
默认情况下,SMAP 保护是开启的。如果是使用 qemu 启动的内核,我们可以在 -append 选项中添加 +smap 来开启 SMAP。
1 | $ grep smap /proc/cpuinfo |
attack SMAP
改cr4寄存器和上面的SMEP很相似。
把 CR4 寄存器中的第 21 位置为 0 后,我们就可以访问用户态的数据。一般而言,我们会使用 0x6f0 来设置 CR4,这样 SMAP 和 SMEP 都会被关闭。
内核中修改 cr4 的代码最终会调用到 native_write_cr4,当我们能够劫持控制流后,我们就可以执行内核中对应的 gadget 来修改 CR4。从另外一个维度来看,内核中存在固定的修改 cr4 的代码,比如在 refresh_pce 函数、set_tsc_mode 等函数里都有。
copy_from_user & copy_to_user
在劫持控制流后,攻击者可以调用 copy_from_user 和 copy_to_user 来访问用户态的内存。这两个函数会临时清空禁止访问用户态内存的标志。
KPTI
KPTI 机制最初的主要目的是为了缓解 KASLR 的绕过以及 CPU 侧信道攻击。
在 KPTI 机制中,内核态空间的内存和用户态空间的内存的隔离进一步得到了增强。
- 内核态中的页表包括用户空间内存的页表和内核空间内存的页表。
- 用户态的页表只包括用户空间内存的页表以及必要的内核空间内存的页表,如用于处理系统调用、中断等信息的内存。
如果是使用 qemu 启动的内核,我们可以在
-append选项中添加kpti=1来开启 KPTI。如果是使用 qemu 启动的内核,我们可以在
-append选项中添加nopti来关闭 KPTI。
可以使用下面的命令看KPTI
1 | $ cat /proc/cpuinfo | grep pti |
attack KPTI
修改页表
在开启 KPTI 后,用户态空间的所有数据都被标记了 NX 权限,但是,我们可以考虑修改对应的页表权限,使其拥有可执行权限。当内核没有开启 smep 权限时,我们在修改了页表权限后就可以返回到用户态,并执行用户态的代码。
SWITCH_TO_USER_CR3_STACK
在开启 KPTI 机制后,用户态进入到内核态时,会进行页表切换;当从内核态恢复到用户态时,也会进行页表切换。那么如果我们可以控制内核执行返回用户态时所执行的切换页表的代码片段,也就可以正常地返回到用户态。
通过分析内核态到用户态切换的代码,我们可以得知,页表的切换主要靠SWITCH_TO_USER_CR3_STACK 汇编宏。因此,我们只需要能够调用这部分代码即可。
1 | .macro SWITCH_TO_USER_CR3_STACK scratch_reg:req |
事实上,我们不仅希望切换页表,还希望能够返回到用户态,因此我们这里也需要复用内核中返回至用户态的代码。内核返回到用户态主要有两种方式:iret 和 sysret。下面详细介绍。
iret
1 | SYM_INNER_LABEL(swapgs_restore_regs_and_return_to_usermode, SYM_L_GLOBAL) |
可以看到,通过伪造如下的栈,然后跳转到 movq %rsp, %rdi,我们就可以同时切换页表和返回至用户态。
1 | fake rax |
sysret
在使用 sysret 时,我们首先需要确保 rcx 和 r11 为如下的取值
1 | rcx, save the rip of the code to be executed when returning to userspace |
然后构造如下的栈
1 | fake rdi |
最后跳转至 entry_SYSCALL_64 的如下代码,即可返回到用户态。
1 | SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi |
内部隔离
根据描述,如果在使用 kmem_cache_create 创建一个 cache 时,传递了 SLAB_ACCOUNT 标记,那么这个 cache 就会单独存在,不会与其它相同大小的 cache 合并。
1 | Currently, if we want to account all objects of a particular kmem cache, |
在早期,许多结构体(如 cred 结构体)对应的堆块并不单独存在,会和相同大小的堆块使用相同的 cache。在 Linux 4.5 版本引入了这个 flag 后,许多结构体就单独使用了自己的 cache。然而,根据上面的描述,这一特性似乎最初并不是为了安全性引入的。
1 | Mark those kmem allocations that are known to be easily triggered from |
访问控制
访问控制是指内核通过对某些对象添加访问控制,使得内核中相应的对象具有一定的访问控制要求,比如不可写,或者不可读。
dmesg_restrict
该选项用于控制是否可以使用 dmesg 来查看内核日志。当 dmesg_restrict 为 0 时,没有任何限制;当该选项为 1 时,只有具有 CAP_SYSLOG 权限的用户才可以通过 dmesg 命令来查看内核日志。
如下图,普通用户没有这个权限

1 | dmesg_restrict: |
kptr_restrict
该选项用于控制在输出内核地址时施加的限制,主要限制以下接口
- 通过 /proc 获取的内核地址
- 通过其它接口(有待研究)获取的地址
具体输出的内容与该选项配置的值有关
- 0:默认情况下,没有任何限制。
- 1:使用
%pK输出的内核指针地址将被替换为 0,除非用户具有 CAP_ SYSLOG 特权,并且 group id 和真正的 id 相等。 - 2:使用
%pK输出的内核指针都将被替换为 0 ,即与权限无关。
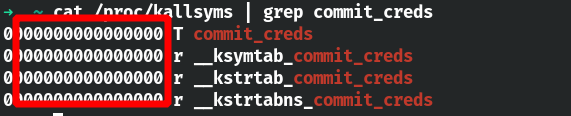
当开启该保护后,攻击者就不能通过 /proc/kallsyms 来获取内核中某些敏感的地址了,如 commit_creds、prepare_kernel_cred。
misc
__ro_after_init
Linux 内核中有很多数据都只会在 __init 阶段被初始化,而且之后不会被改变。使用 __ro_after_init 标记的内存,在 init 阶段结束后,不能够被再次修改。
我们可以使用 set_memory_rw(unsigned long addr, int numpages) 来修改对应页的权限。
mmap_min_addr
mmap_min_addr 是用来对抗 NULL Pointer Dereference 的,指定用户进程通过 mmap 可以使用的最低的虚拟内存地址。
异常检测
通过对内核中发生的异常行为进行检测,我们可以缓解一定的攻击。
Kernel Stack Canary
Canary 是一种典型的检测机制。在 Linux 内核中,Canary 的实现是与架构相关的,所以这里我们分别从不同的架构来介绍。
正常的pwn栈题里有时也会开canary,想必应该知道什么意思吧。:)
在 x86 架构中,同一个 task 中使用相同的 Canary。
在编译内核时,我们可以设置 CONFIG_CC_STACKPROTECTOR 选项,来开启该保护。
我们需要重新编译内核,并关闭编译选项才可以关闭 Canary 保护。
根据 x86 架构下 Canary 实现的特点,我们只要泄漏了一次系统调用中的 Canary,同一 task 的其它系统调用中的 Canary 也就都被泄漏了。
随机化
内核中可以使用随机性来提高安全性
KASLR
在开启了 KASLR 的内核中,内核的代码段基地址等地址会整体偏移。
如果是使用 qemu 启动的内核,我们可以在 -append 选项中添加 kaslr 来开启 KASLR。
如果是使用 qemu 启动的内核,我们可以在 -append 选项中添加 nokaslr 来关闭 KASLR。
通过泄漏内核某个段的地址,就可以得到这个段内的所有地址。比如当我们泄漏了内核的代码段地址,就知道内核代码段的所有地址。
FGKASLR
鉴于 KASLR 的不足,有研究者实现了 FGKASLR。FGKASLR 在 KASLR 基地址随机化的基础上,在加载时刻,以函数粒度重新排布内核代码。
FGKASLR 的实现相对比较简单,主要在两个部分进行了修改。目前,FGKASLR 只支持 x86_64 架构。
编译阶段
FGKASLR 利用 gcc 的编译选项 -ffunction-sections 把内核中不同的函数放到不同的 section 中。 在编译的过程中,任何使用 C 语言编写的函数以及不在特殊输入节的函数都会单独作为一个节;使用汇编编写的代码会位于一个统一的节中。
编译后的 vmlinux 保留了所有的节区头(Section Headers),以便于知道每个函数的地址范围。同时,FGKASLR 还有一个重定位地址的扩展表。通过这两组信息,内核在解压缩后就可以乱序排列函数。
最后的 binary 的第一个段包含了一个合并节(由若干个函数合并而成)、以及若干其它单独构成一个节的函数。
加载阶段
在解压内核后,会首先检查保留的符号信息,然后寻找需要随机化的 .text.* 节区。其中,第一个合并的节区 (.text) 会被跳过,不会被随机化。后面节区的地址会被随机化,但仍然会与 .text 节区相邻。同时,FGKASLR 修改了已有的用于更新重定位地址的代码,不仅考虑了相对于加载地址的偏移,还考虑了函数节区要被移动到的位置。
为了隐藏新的内存布局,/proc/kallsyms 中符号使用随机的顺序来排列。在 v4 版本之前,该文件中的符号按照字母序排列。
通过分析代码,我们可以知道,在 layout_randomized_image 函数中计算了最终会随机化的节区,存储在 sections 里。
1 | /* |
可以看到,只有同时满足以下条件的节区才会参与随机化
- 节区名以 .text 开头
- section flags 中包含
SHF_ALLOC - section flags 中包含
SHF_EXECINSTR
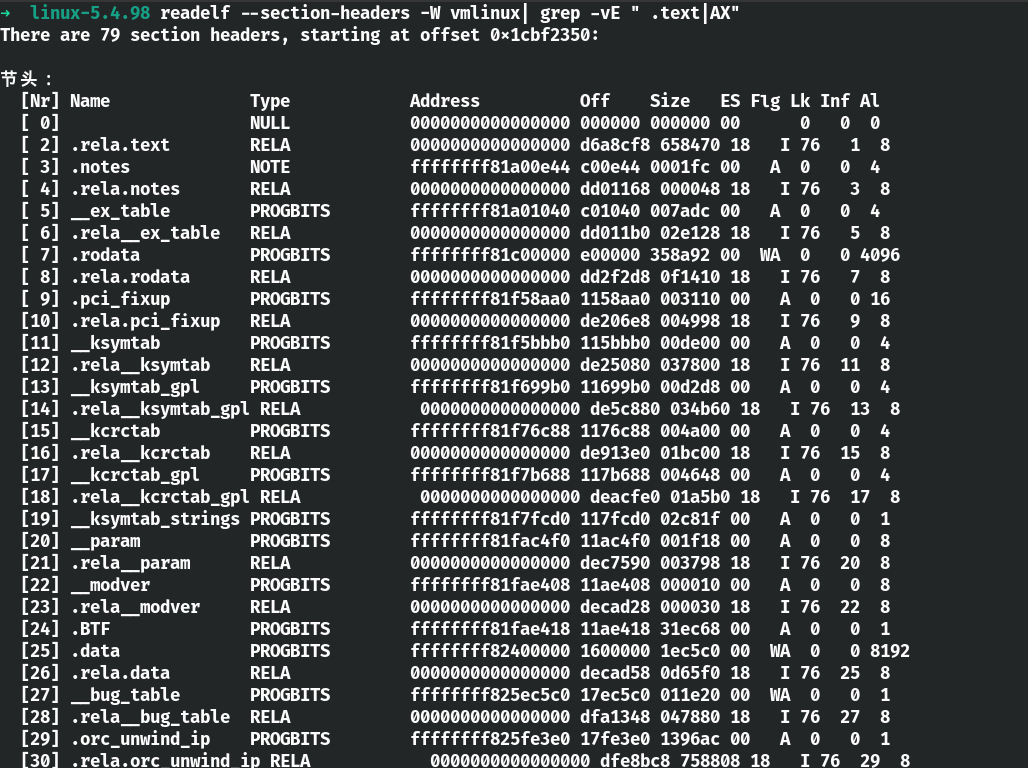
因此,通过以下命令,我们可以知道
- __ksymtab 不会参与随机化
- .data 不会参与随机化
启动阶段
在启动阶段,FGKASLR
- 需要解析内核的 ELF 文件来获取需要随机化的节区。
- 会调用随机数生成器来确定每个节区需要存储的地址,并进行布局。
- 会将原有解压的内核拷贝到另外一个地方,以便于避免内存破坏。
- 会增加内核需要重定位的次数。
- 需要检查每一个需要重定位的地址是否位于随机化的节区,如果是的话,需要调整一个新的偏移。
- 会重新排列那些需要按照地址排序的数据表。
在一个现代化的系统上,启动一个测试的 VM,大概花费了 1s。
运行阶段
运行阶段的开开启销其实主要取决于具体的负载。不过由于原先相邻的函数可能被随机化被放在不同的地址,所以相对而言,整体性能应该会有所降低。
open & close
如果想要开启内核的 FGKASLR,你需要开启 CONFIG_FG_KASLR=y 选项。
FGKASLR 也支持模块的随机化,尽管 FGKASLR 只支持 x86_64 架构下的内核,但是该特性可以支持其它架构下的模块。我们可以使用 CONFIG_MODULE_FG_KASLR=y 来开启这个特性。
通过在命令行使用 nokaslr 关闭 KASLR 也同时会关闭 FGKASLR。当然,我们可以单独使用 nofgkaslr 来关闭 FGKASLR。
缺点
根据 FGKASLR 的特点,我们可以发现它具有以下缺陷
函数粒度随机化,如果函数内的某个地址知道了,函数内部的相对地址也就知道了。
.text节区不参与函数随机化。因此,一旦知道其中的某个地址,就可以获取该节区所有的地址。有意思的是系统调用的入口代码都在该节区内,主要是因为这些代码都是汇编代码。此外,该节区具有以下一些不错的 gadget
- swapgs_restore_regs_and_return_to_usermode,该部分的代码可以帮助我们绕过 KPTI 防护
- memcpy 内存拷贝
- sync_regs,可以把 RAX 放到 RDI 中
__ksymtab相对于内核镜像的偏移是固定的。因此,如果我们可以泄露数据,那就可以泄露出其它的符号地址,如 prepare_kernel_cred、commit_creds。具体方式如下
- 基于内核镜像地址获取 __ksymtab 地址
- 基于 __ksymtab 获取对应符号记录项的地址
- 根据符号记录项中具体的内容来获取对应符号的地址
data 节区相对于内核镜像的偏移也是固定的。因此在获取了内核镜像的基地址后,就可以计算出数据区数据的地址。这个节区有一些可以重点关注的数据
- modprobe_path
Reference
https://ctf-wiki.org/pwn/linux/kernel-mode/defense/readme/
https://github.com/torvalds/linux/commit/15385dfe7e0fa6866b204dd0d14aec2cc48fc0a7