CISCN和强网就出了LLVM PASS PWN,笔者没有接触过就直接跳过了,但是随着pwn的难度越来越高LLVM PASS PWN在笔者看来出题的次数会越来越多,笔者写下这一系列文章来记录学习LLVM PASS PWN,如有错误欢迎指正
LLVM PASS PWN(一) 前置知识简述 为什么要编译程序 机器语言是用1和0组成的代码,但机器是识别不了1和0的,更具体的是如何识别的呢?对机器电路进行设计之后,机器能识别高电平还是低电平,刚好与2进制很相似,想输入0就给机器输入低电平,想输入1,就给机器输入高电平,所以就看到了1和0的表示形式
机器语言它是计算机唯一能识别和执行的语言,但它的直观性差,可读性差,比如一串11110000111100001111机器可以快速识别是什么但是我们很难理解,再比如我们想要在屏幕上输出hello world那我们该如何用二进制来表示呢,所以汇编语言就诞生了
汇编语言用助记符来表示机器指令中的操作码和操作数的指令系统,如a = 1,我们不需要去用二进制来理解,我们完全可以利用mov a, 1进行理解,那有没有更简单的方法呢,比如现在要输出hello wrold,还是需要十几行的汇编代码的,所以高级语言就诞生了
高级语言是一种更接近人类的自然语言和数学语言的语言,比如想要a = 1,很直观就是a = 1,在很大程度上减少编程人员的编写量
但是问题来了,机器只懂0和1那怎么才能让高级语言被机器识别,所以就有了编译,将高级语言(源语言)翻译成汇编语言或机器语言(目标语言),编译的根本目的就是把源代码变成目标代码
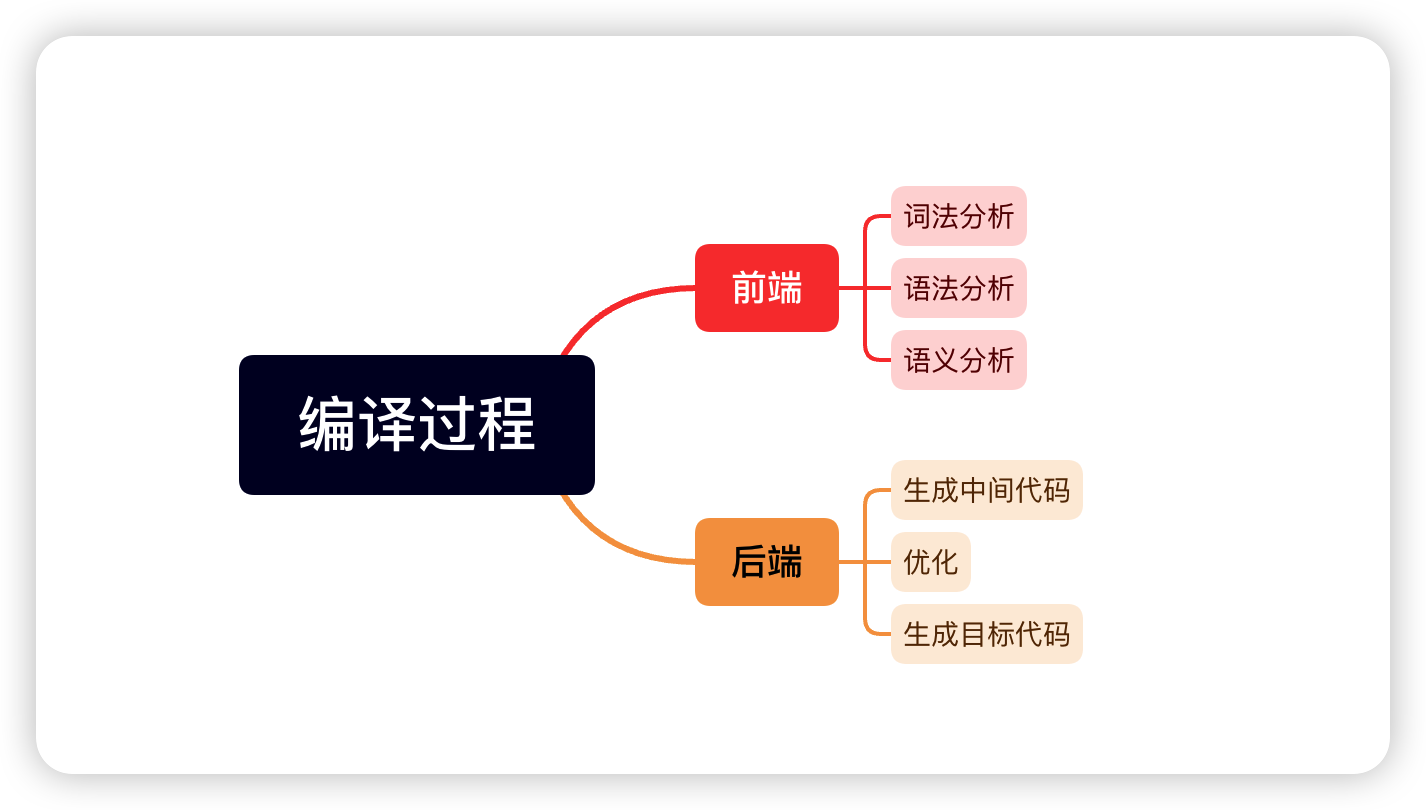
编译的过程是什么 编译过程主要可以划分为前端与后端,笔者用一张图简述一下
前端把源代码翻译成IR,后端把IR编译成目标平台的机器码,这里笔者在查阅资料的时候发现有些会将生成中间代码放入前端,而有些资料会将生成中间代码放入后端
在词法分析中编译器读入源代码,经过词法分析器识别出Token,比如词法分析器中识别出的Token可以是int, return, {, }等
在语法分析中会把上面的Token串给转换成一个抽象语法树AST,AST树反映了程序的语法结构
在语义分析中需要做的任务是理解语义,语句要做什么,如for是需要去实现循环,if是判断等
在前端完成之后,会生成中间代码,统一优化中间代码,再去将中间代码生成目标代码
前置知识这里笔者简述了一下,具体的可以移步编译原理
LLVM LLVM IR & LLVM Pass gcc这个最经典的编译器提供的是一整套服务,前端和后端耦合在了一起,导致了如果一个新的编程语言出现可能需要设计一个新的IR以及实现这个IR的后端,如果出现了一个新的平台就要实现一个从自己的IR到新平台的后端,针对此类问题就出现了LLVM
不同的前后端使用统一的中间代码,这样一个新的编程语言出现只需要实现一个新的前端,如果出现了一个新的平台只需要实现一个新的后端
LLVM IR有三种表示形式
可读IR,类似汇编代码,可以给人看的,后缀.ll
不可读二进制IR,后缀.bc
保存在内存中,内存格式
LLVM Pass 是一个框架设计,是LLVM系统里重要的组成部分,因为LLVM Pass负责LLVM编译器绝大部分的工作,一系列的Pass组合,构建了编译器的转换和优化部分,抽象成结构化的编译器代码。
在实现上,LLVM的核心库中会给你一些 Pass类 去继承。你需要实现它的一些方法。 最后使用LLVM的编译器会把它翻译得到的IR传入Pass里,给你遍历和修改。
LLVM Pass的用处是插桩,机器无关的代码优化,静态分析,代码混淆等
LLVM 工具 以下内容来自LLVM Pass入门导引
llvm-as:把LLVM IR从人类能看懂的文本格式汇编成二进制格式。注意:此处得到的不是 目标平台的机器码。llvm-dis:llvm-as的逆过程,即反汇编。 不过这里的反汇编的对象是LLVM IR的二进制格式,而不是机器码。opt:优化LLVM IR。输出新的LLVM IR。llc:把LLVM IR编译成汇编码。需要用as进一步得到机器码。lli:解释执行LLVM IR。
Clang Clang 是 LLVM 的前端,可以用来编译 C,C++,ObjectiveC 等语言。Clang 的功能包括:词法分析、语法分析、语义分析、生成中间中间代码LLVM Intermediate Representation (LLVM IR)。
LLVM & Clang环境安装 & 工具测试 ubuntu20.04下安装LLVM + Clang如下
sudo apt install clang-12
sudo apt install clang-8
sudo apt install llvm-12
sudo apt install llvm-8
llvm-12安装之后可以使用opt-12,今年的ciscn的LLVM PASS PWN就是opt-12,一般题目都会给出opt的版本。ubuntu20.04应该自带opt-10如果没有的话,sudo apt install clang-10 && sudo apt install llvm-10
上面的做题环境都安装完成之后,先写一个c文件,利用Clang将c文件编译成.ll, .bc等格式看一下是否是如上所说,c文件如下
1 2 3 4 5 6 7 8 9 10 11 #include <stdio.h> #include <unistd.h> int main (int argc, char **argv) { char name[0x20 ]; puts ("hello world" ); puts ("plz input your name" ); read(0 , name, 0x1F ); printf ("biubiubiu" ); return 0 ; }
首先是.c->.ll,clang-12 -emit-llvm -S test.c -o test.ll,test.ll(生成的IR文本文件)如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 ; ModuleID = 'test.c' source_filename = "test.c" target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128" target triple = "x86_64-pc-linux-gnu" @.str = private unnamed_addr constant [12 x i8] c"hello world\00" , align 1 @.str.1 = private unnamed_addr constant [20 x i8] c"plz input your name\00" , align 1 @.str.2 = private unnamed_addr constant [10 x i8] c"biubiubiu\00" , align 1 ; Function Attrs: noinline nounwind optnone uwtable define dso_local i32 @main(i32 %0 , i8** %1 ) #0 { %3 = alloca i32, align 4 %4 = alloca i32, align 4 %5 = alloca i8**, align 8 %6 = alloca [32 x i8], align 16 store i32 0 , i32* %3 , align 4 store i32 %0 , i32* %4 , align 4 store i8** %1 , i8*** %5 , align 8 %7 = call i32 @puts (i8* getelementptr inbounds ([12 x i8], [12 x i8]* @.str, i64 0 , i64 0 )) %8 = call i32 @puts (i8* getelementptr inbounds ([20 x i8], [20 x i8]* @.str.1 , i64 0 , i64 0 )) %9 = getelementptr inbounds [32 x i8], [32 x i8]* %6 , i64 0 , i64 0 %10 = call i64 @read(i32 0 , i8* %9 , i64 31 ) %11 = call i32 (i8*, ...) @printf (i8* getelementptr inbounds ([10 x i8], [10 x i8]* @.str.2 , i64 0 , i64 0 )) ret i32 0 } declare dso_local i32 @puts (i8*) #1 declare dso_local i64 @read(i32, i8*, i64) #1 declare dso_local i32 @printf (i8*, ...) #1 attributes #0 = { noinline nounwind optnone uwtable "disable-tail-calls" ="false" "frame-pointer" ="all" "less-precise-fpmad" ="false" "min-legal-vector-width" ="0" "no-infs-fp-math" ="false" "no-jump-tables" ="false" "no-nans-fp-math" ="false" "no-signed-zeros-fp-math" ="false" "no-trapping-math" ="true" "stack-protector-buffer-size" ="8" "target-cpu" ="x86-64" "target-features" ="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu" ="generic" "unsafe-fp-math" ="false" "use-soft-float" ="false" } attributes #1 = { "disable-tail-calls" ="false" "frame-pointer" ="all" "less-precise-fpmad" ="false" "no-infs-fp-math" ="false" "no-nans-fp-math" ="false" "no-signed-zeros-fp-math" ="false" "no-trapping-math" ="true" "stack-protector-buffer-size" ="8" "target-cpu" ="x86-64" "target-features" ="+cx8,+fxsr,+mmx,+sse,+sse2,+x87" "tune-cpu" ="generic" "unsafe-fp-math" ="false" "use-soft-float" ="false" } !llvm.module.flags = !{!0 } !llvm.ident = !{!1 } !0 = !{i32 1 , !"wchar_size" , i32 4 } !1 = !{!"Ubuntu clang version 12.0.0-3ubuntu1~20.04.5" }
上面的IR很直观,之前提到LLVM PASS的一个用处是优化IR代码,会将上面的可以优化的进行优化
其次是.c->.bc,clang-12 -emit-llvm -c test.c -o test.bc,bc是不可读二进制
然后是.ll -> .bc,llvm-as test.ll -o test.bc,结果和上面的一样
接着是.bc - > .ll,llvm-dis test.bc -o test.ll,同上
最后还有一个.bc -> .s, llc test.bc -o test.s,将字节码的二进制格式文件转换为本地的汇编文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 .text .file "test.c" .globl main # -- Begin function main .p2align 4 , 0x90 .type main,@function main: # @main .cfi_startproc # %bb.0 : pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset %rbp, -16 movq %rsp, %rbp .cfi_def_cfa_register %rbp subq $48 , %rsp movl $0 , -8 (%rbp) movl %edi, -4 (%rbp) movq %rsi, -16 (%rbp) movabsq $.L.str, %rdi callq puts movabsq $.L.str.1 , %rdi callq puts leaq -48 (%rbp), %rsi xorl %edi, %edi movl $31 , %edx callq read movabsq $.L.str.2 , %rdi movb $0 , %al callq printf xorl %eax, %eax addq $48 , %rsp popq %rbp .cfi_def_cfa %rsp, 8 retq .Lfunc_end0: .size main, .Lfunc_end0-main .cfi_endproc # -- End function .type .L.str,@object # @.str .section .rodata.str1.1 ,"aMS" ,@progbits,1 .L.str: .asciz "hello world" .size .L.str, 12 .type .L.str.1 ,@object # @.str.1 .L.str.1 : .asciz "plz input your name" .size .L.str.1 , 20 .type .L.str.2 ,@object # @.str.2 .L.str.2 : .asciz "biubiubiu" .size .L.str.2 , 10 .ident "Ubuntu clang version 12.0.0-3ubuntu1~20.04.5" .section ".note.GNU-stack" ,"" ,@progbits
编写第一个LLVM Pass 通过前面的知识之后,现在可以尝试编写“hello world”的pass,下面是官方 的示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 #include "llvm/Pass.h" #include "llvm/IR/Function.h" #include "llvm/Support/raw_ostream.h" #include "llvm/IR/LegacyPassManager.h" #include "llvm/Transforms/IPO/PassManagerBuilder.h" using namespace llvm; namespace { struct Hello : static char ID; Hello() : FunctionPass(ID) {} bool runOnFunction (Function &F) override { errs() << "Hello: " ; errs().write_escaped(F.getName()) << '\n' ; return false ; } }; } char Hello::ID = 0 ;static RegisterPass<Hello> X ("hello" , "Hello World Pass" , false , false ) ;static RegisterStandardPasses Y ( PassManagerBuilder::EP_EarlyAsPossible, [](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) { PM.add(new Hello()); }) ;
先声明pass本身,然后声明了一个Hello类,它是FunctionPass的子类。稍后将详细描述不同的内置pass子类,但是现在知道FunctionPass一次对一个函数进行操作。
然后声明了LLVM用于标识pass的pass标识符。 这允许LLVM避免使用昂贵的C ++运行时信息,如下
1 2 static char ID;Hello() : FunctionPass(ID) {}
然后声明了一个runOnFunction方法,它覆盖了从FunctionPass继承的抽象虚方法。 这是我们应该做的事情,所以我们只用每个函数的名称打印出我们的消息。代码如下
1 2 3 4 5 6 7 bool runOnFunction (Function &F) override { errs() << "Hello: " ; errs().write_escaped(F.getName()) << '\n' ; return false ; } }; }
接着初始化passID。 LLVM使用ID的地址来标识pass,因此初始化值并不重要。代码如下
最后,我们注册我们的类Hello,给它一个命令行参数“hello”,并命名为“Hello World Pass”。 最后两个参数描述了它的行为:如果传递遍历CFG而不修改它,那么第三个参数设置为true; 如果pass是分析pass,例如支配树pass,则提供true作为第四个参数。代码如下
1 2 3 static RegisterPass<Hello> X ("hello" , "Hello World Pass" , false , false ) ;
如果我们想将通道注册为现有管道的一个步骤,则提供了一些扩展点,例如PassManagerBuilder::EP_EarlyAsPossible在任何优化之前应用我们的通道,或者PassManagerBuilder::EP_FullLinkTimeOptimizationLast 在链接时间优化之后应用它。代码如下
1 2 3 4 static llvm::RegisterStandardPasses Y ( llvm::PassManagerBuilder::EP_EarlyAsPossible, [](const llvm::PassManagerBuilder &Builder, llvm::legacy::PassManagerBase &PM) { PM.add(new Hello()); }) ;
现在需要将这个Pass编译成模块,使用如下命令即可
1 clang-12 `llvm-config --cxxflags` -Wl,-znodelete -fno-rtti -fPIC -shared Hello.cpp -o LLVMHello.so `llvm-config --ldflags`
现在应该会看到LLVMHello.so这个文件,通过官方文档可知需要使用以下命令
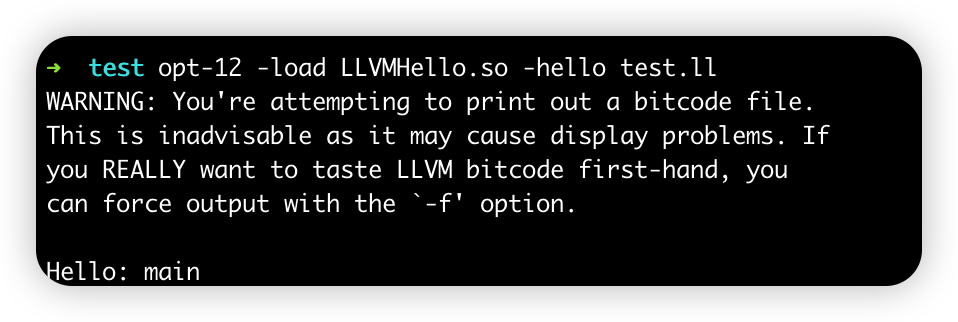
1 opt -load LLVMHello.so -hello test.ll
这里的 -hello由Hello.cpp中的static RegisterPass<Hello> X参数决定
但是笔者这里报了一个错Error opening 'LLVMHello.so': LLVMHello.so: cannot open shared object file: No such file or directory,这是因为linux无法在默认地址找到LLVMHello.so,解决很简单sudo cp LLVMHello.so /lib
成功输出test.c所有函数名称
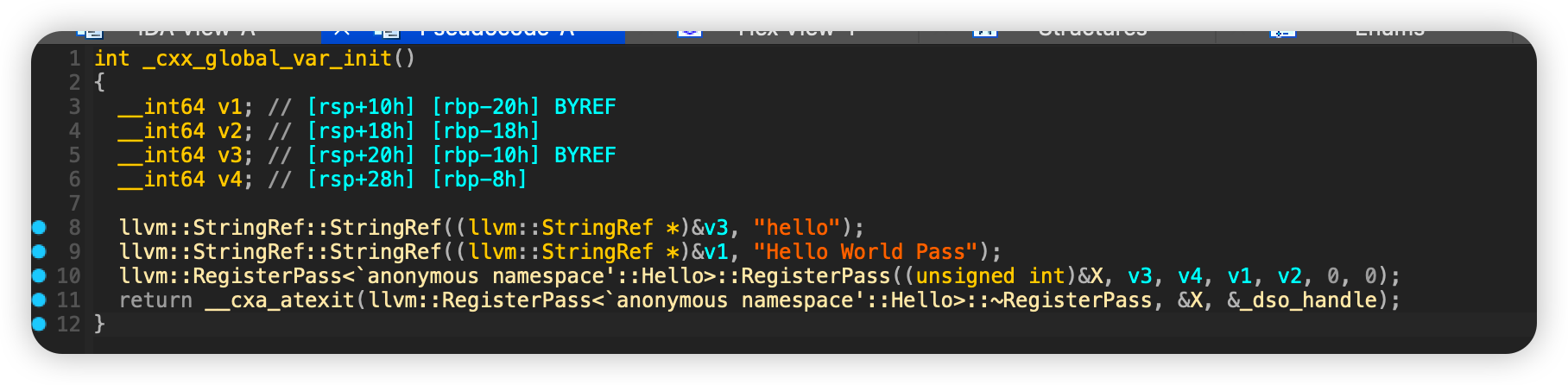
对第一个LLVM Pass逆向分析 刚刚生成了LLVMHello.so这个pass文件,比赛题和上面也一样,会重写FunctionPass类中的runOnFunction函数,所以我们对上面的示例程序进行逆向分析,看一下虚表位置这样方便比赛的时候确定每个函数的位置
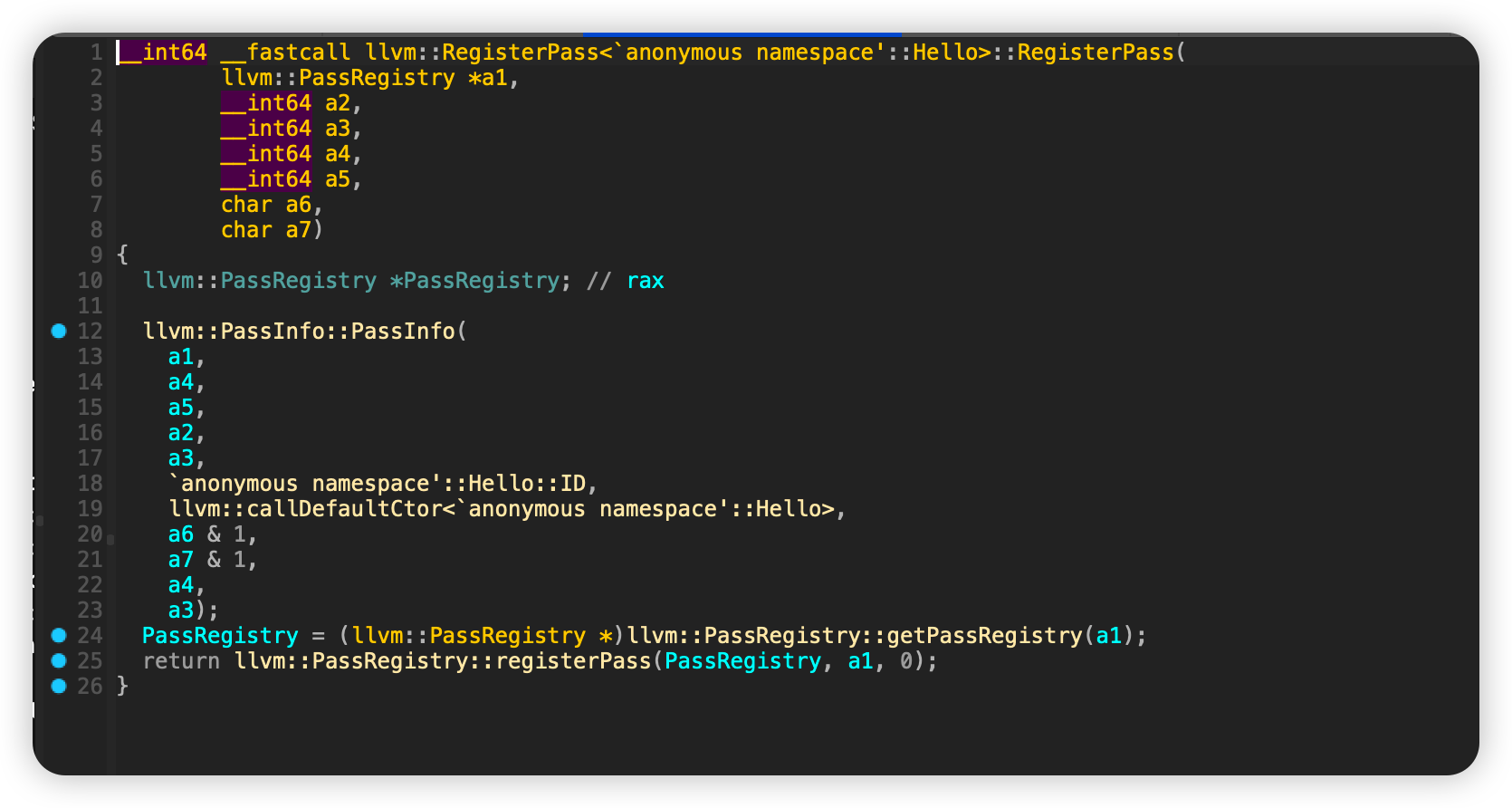
跟进RegisterPass
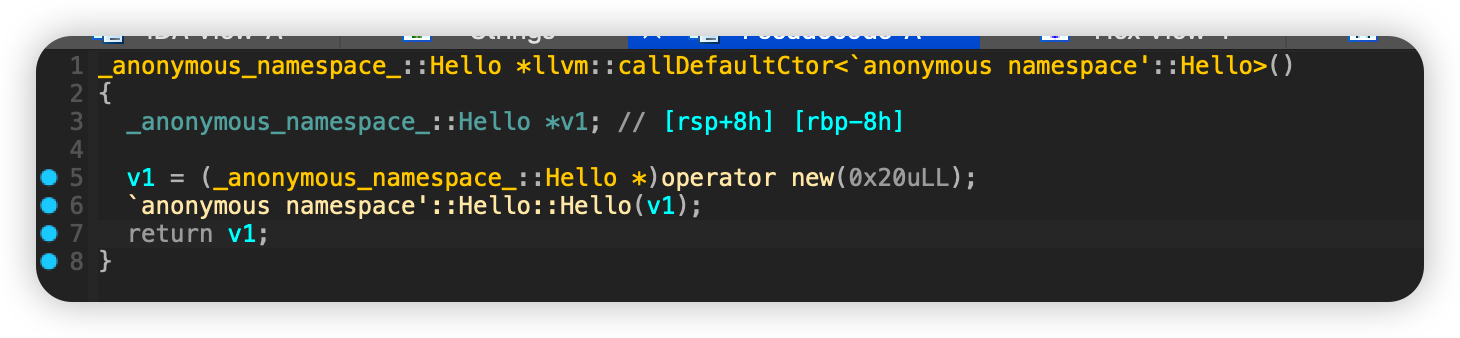
发现调用了callDefaultCtor进行对象创建,跟进它
给Hello对象分配了0x20个空间,跟进Hello
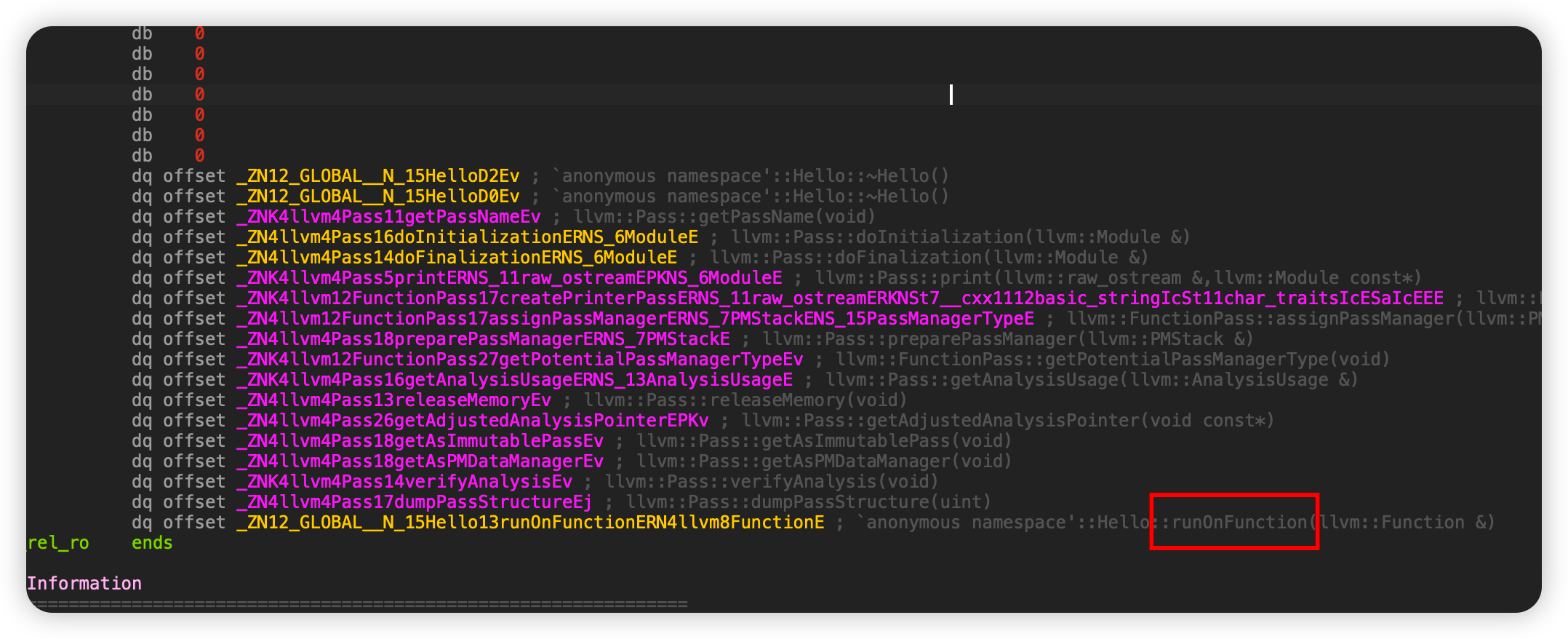
看到虚表了,直接跟进
runOnFunction函数位于虚表中的最后一个位置,因为runOnFunction函数被我们重写了,所以它指向的是我们自定义的那个函数,比赛题的漏洞基本就是这个,所以在做LLVM Pass pwn的时候定位函数的位置可以从虚表入手
总结 收获很大,从编译过程到LLVM,加固了计算机底层的一些知识,知道了LLVM PASS PWN该怎么入手,以前看到LLVM PASS PWN的时候都不知道怎么运行(XD),这里第一篇就结束了,后面笔者会继续更新
Reference https://zhuanlan.zhihu.com/p/130702001
https://zhuanlan.zhihu.com/p/122522485
https://www.homedt.net/196837.html
https://llvm.org/docs/WritingAnLLVMPass.html